


We built fcr-simulator to answer a simple question: if the Fast Confirmation Rule had already been running on mainnet, what would it have done?
To study this, we replayed historical mainnet beacon chain data through 4 consensus-layer client implementations of FCR. Each client saw the same blocks, the same attestations, and the same cutoff rules. We then compared how each implementation classified each slot.
This post describes the simulator, the dataset, the infrastructure we used to run the replays, and the results from the v0.2.0 dataset.
For background on FCR itself, fastconfirm.it is the best place to start.
The simulator
The simulator is intentionally narrow. Its job is to feed the same mainnet history and attestation data into multiple FCR implementations, then record the result for every slot.
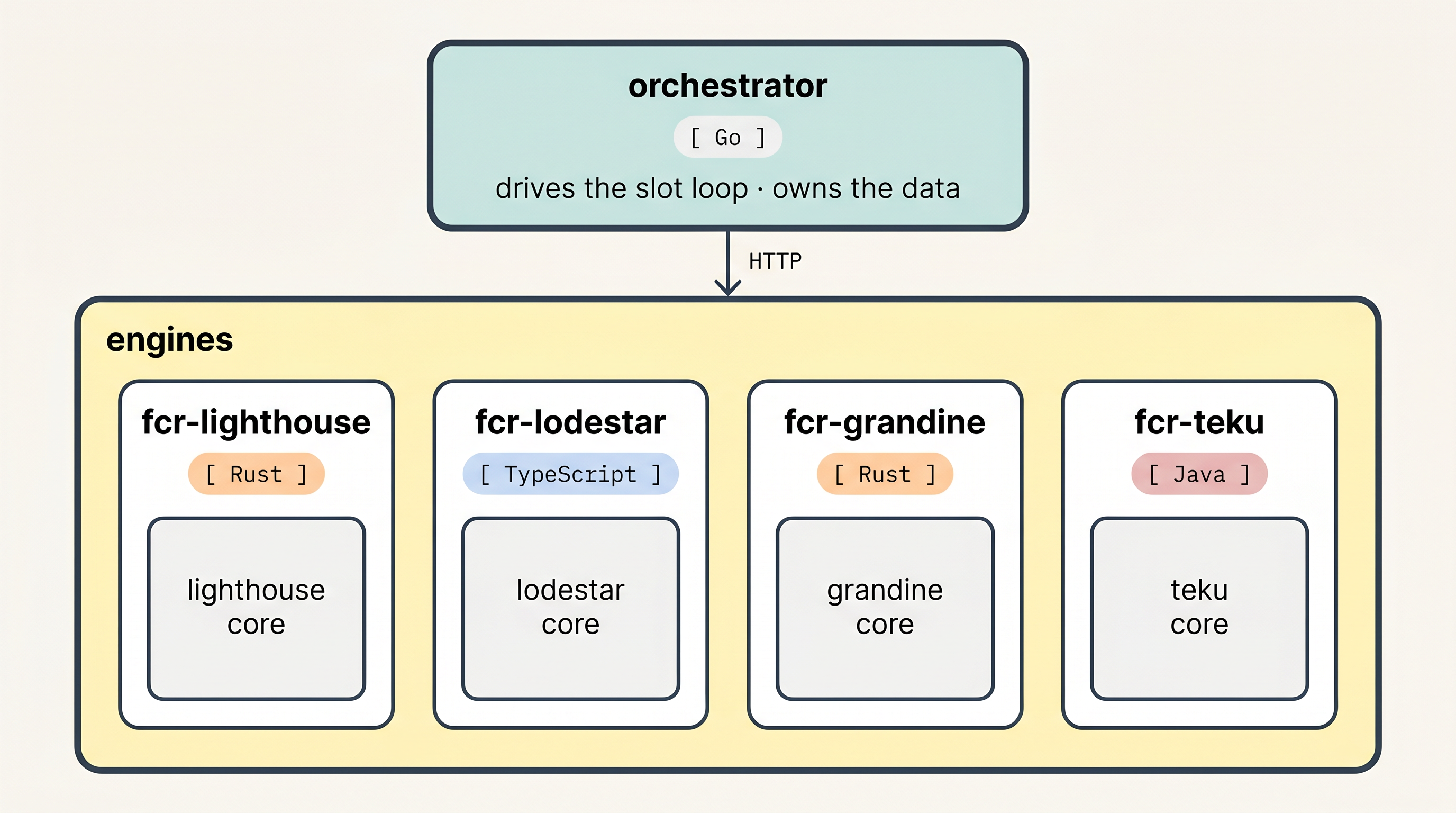
At the centre of the system is an orchestrator. The orchestrator takes a job specification, starts an engine such as lighthouse, and provides that engine with the data it needs. The engine calls back to the orchestrator over HTTP.
This separation is a large step for reproducibility. The orchestrator is responsible for fetching blocks and attestations, while each client implementation is responsible for applying its FCR logic. That keeps the multi-client simulator easier to reason about, and it means we can swap or replay datasources without reimplementing data loading separately in every client.
We also "warm" the beacon nodes before the simulation run to hydrate their fork choice store and any caches. For the run below, we warmed each beacon node with 10 epochs worth of attestations.
The data
The simulator uses data we already had from other ethpandaops infrastructure:
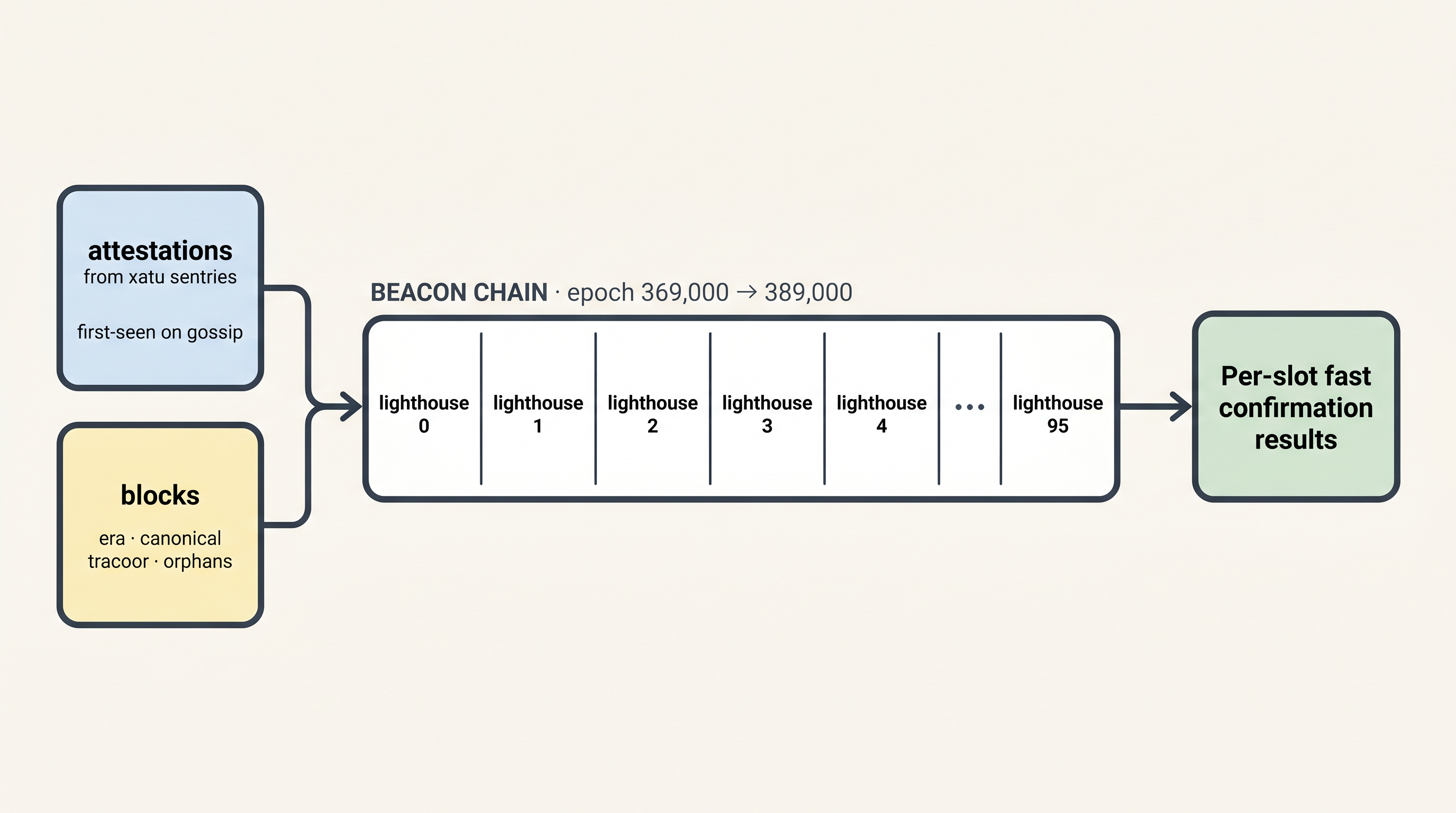
- Blocks
- Canonical blocks from
erafiles, using the Nimbus team’s mirror - Orphaned blocks from ethpandaops/tracoor
- Canonical blocks from
- Attestations
- Single Attestations from ethpandaops/xatu that voted for each block before the 12 second cutoff
The attestation dataset is not a perfect recreation of what a beacon node would have experienced at the time. For some slots, this view of the network may report more attestations than your average beacon node. Conversely, for other slots, this view may have less attestations. This data also completely ignores aggregate attestations. We assume that attestation aggregation is steady and reliable on Mainnet as this is where most nodes would get 62/64 of their attestations from.
Running the simulations
Replaying a year of mainnet through fork choice one slot at a time would be too slow to be useful. The slot state transition is expensive, and repeated queries against the Xatu database would add more overhead.
To make the experiment practical, we ran the replay as a sharded Kubernetes job. We also ran a one-off query against Xatu and stored the result in our in-house S3 cluster. This gave every run the same input data and avoided repeatedly querying the database during simulation.
We ran the simulations in 1 to 3 month epoch ranges. This was mostly a practical choice: if a job failed near the end of a long run, we wanted to limit how much work could be lost or need to be discarded.
After benchmarking, we ran 96 beacon nodes across 6 Hetzner AX162 servers. Each server ran 16 beacon nodes. We also mounted each client database into RAMFS to minimize the expensive disk reads and writes.
The workload was heavily memory bound, but this setup still gave us a roughly 25x to 35x speedup compared with a sequential replay.
Results
About 31 hours of slots, or 0.36% of the dataset, are excluded from every chart and number below. This consists of 9 Xatu pipeline issues totalling about 22 hours, and one 8.4 hour simulator feeder bug on 2026-04-01.
Coverage
| Client | Epoch range | Dates (UTC) | Slots |
|---|---|---|---|
| Lighthouse | 369,000 to 449,000 | 2025-05-29 to 2026-05-20 | 2,560,000 |
| Lodestar | 417,500 to 449,000 | 2025-12-31 to 2026-05-20 | 1,008,000 |
| Grandine | 423,800 to 449,000 | 2026-01-28 to 2026-05-20 | 806,400 |
| Teku | 423,800 to 449,000 | 2026-01-28 to 2026-05-20 | 806,400 |
What we found
The most important number first: zero false confirmations. Across 5.15 million slot evaluations and all four clients, no implementation ever fast-confirmed a block that turned out to be non-canonical on the finalized chain. The simulator checks each engine's confirmed_root against the ERA-file canonical block at that slot during the merge step, and across the entire 12-month period (including the December 4 2025 Fusaka mainnet instability) there are zero mismatches.
Headline rate: across 800,000 mainnet slots in the comparable window, roughly 96 out of every 100 slots would have been fast-confirmed within 12 seconds.
Three of the four clients agree almost exactly on which slots qualify. Lighthouse and Grandine report identical 1-slot rates to four decimal places (95.8165%) and agree on every single slot in the shared window. Lodestar lands at 95.8164%, which is a single-slot difference across ~800k. Effectively identical.
Teku is the odd one out. It reports 97.3926%, marking ~12,500 more slots as fast-confirmed than the others over the same window.
Reproducibility
Every CSV in the v0.2.0 release is pinned to a specific engine image tag. Each engine image tag is pinned to an upstream git ref.
The full mapping is in the release METADATA.json, including:
- schema
- run parameters
- attestation source mode
- per-CSV image SHA
- per-engine upstream commit
You can download the dataset with:
curl -L https://github.com/ethpandaops/fcr-simulator/releases/download/v0.2.0/fcr-data-2026-05-26.tar -o fcr-data.tar
tar -xf fcr-data.tar
The orchestrator and engines are available at https://github.com/ethpandaops/fcr-simulator
Love,
EthPandaOps Team