


Introduction
Fusaka has just launched on the Holesky testnet, and it's quickly approaching Mainnet. The fork includes a new feature called PeerDAS which is a new way to distribute blobs to nodes on the network. In PeerDAS, nodes will be responsible for "custodying" different pieces of the blob data determined by the amount of ETH they're validating with. The idea is pretty simple: if you have a lot of ETH staked you probably should have enough resources to handle more blobs, and vice versa. This preserves decentralization ensuring to not exclude home stakers from the network while still providing the benefits of a larger blob count.
This post will focus on the bandwidth and disk usage requirements for various types of nodes on the network after Fusaka.
We'll approach this analysis from two different angles:
- The theoretical requirements for nodes on the network
- What we observed from testing on devnets
PeerDAS
PeerDAS divides our existing 128kB blobs into 128 columns of ~2KB each. These columns are then broadcast individually on the peer-to-peer layer, and nodes custody different subsets of these columns based on the amount of ETH they're validating with. Read more about PeerDAS on ethereum.org.
With the addition of erasure coding (2x blob size), this enables a theoretical 8x scaling limit compared to the current "everyone downloads everything" model. Nodes can verify data availability through sampling without storing complete blobs. This introduces new types of nodes that are possible on the network with different requirements for each.
Three node types emerge:
- Supernode/Backbone node: Validators with combined balance ≥4,096 ETH must subscribe to all 128 column subnets and custody all data for 4096 epochs (~18 days). These nodes are basically forming the backbone of the network. They will have a higher processing and p2p load than the other nodes on the network. However, the stake they represent is non-trivial and these are likely sophisticated entities.
- Validating node: Regular validators (with 1 validator) subscribe to their assigned 8+ random column subnets. Therefore, they would process 1/8th (or more) of the data a supernode would, implying lower p2p,disk and CPU load. This is the benefit that the average home staker would receive.
- Full node: Non-validating nodes participating in 4 column subnets. They would process exactly 1/32th the data a supernode would, implying significantly lower p2p, disk and CPU load. However they still contribute to data availability even without the staking requirement. This is mostly a benefit for the average RPC node that is primarily interested in the state. (Note: If you intend to provide blobs over the Beacon API you should be a supernode as you require all the columns to reconstruct the blob.)
BPOs
Fusaka also introduces the concept of a Blob Parameter Only fork via EIP-7892. These are forks that can only modify the blob count values without the coordination overhead of a full hard fork. Core devs are currently planning on shipping Fusaka with BPO1 and BPO2 to monitor the effects on Mainnet, and will then proceed with more aggressive scaling for BPO3, BPO4, etc, once data has been collected and analysed.
Based on testing and data collected over devnets we arrived at the following proposal for a blob schedule for mainnet:
Theoretical Requirements
The Ethereum network is a complex and evolving system, and its very difficult to nail down the exact requirements for the network after Fusaka given the amount of moving parts. However, we can make some educated guesses based on the current state of the network and the proposed changes.
To help us understand the requirements for the network after Fusaka we'll start by understanding the current state of the network. Mainnet is currently running with 6 Target 9 Max blobs. The Target blob count is the one thats important here as it's the equilibrium point of the blob fee market and we can roughly expect blob count usage to trend there over time.
Reminder: Pre-Fusaka Blobs are 128kB. Post-Fusaka Blobs are 256kB (128kB for the blob, 128kB for the erasure coding.)
To help, we've created a resource calculator that can help identify the requirements for different node types and blob counts. This data needs to be taken with a grain of salt as it is theoretical and assumes a few things. Make sure you change the node type to see the different requirements, and to check the notes for each metric below.
Those who flicked through the calculator will have noticed that there is a significant increase in the requirements for local block building. This is a result of the new erasure coding. Given EIP-7870 the maximum upload bandwidth for a local block builder is 50mb, but our theoretical calculator shows we surpass that with the BPO1 blob count value of 10! What gives? Luckily core devs have a few tricks up their sleeves to help with this:
1. Distributed Blob Building
When a block is built locally the proposer publishes the block and then all 128 columns. When another node receives the block it will first check it's own mempool for the blobs referenced in the block. If it finds them it is able to skip the download and use the local blobs instead. The main benefit here is that the time for a block to be attestable is reduced for the validator as it doesn't have to wait for the blobs to be received via gossip. This has a direct benefit to the block proposer as their proposed blocks will be attestable quicker. There is also the nice side effect of the receiving node potentially being able to avoid downloading the blobs via gossipsub.
2. Using a MEV-Relay
With 86% of blocks being provided by MEV Relays over the last 14 days, the reality is that a significant portion of the network will have the help of a MEV Relay to publish their blocks. While we don't want to rely on these centralized entities, they are a fact of mainnet, and combined with the other two tricks above, we have confidence that the network will handle the load.
3. --max-blobs flag
Consensus Layer clients may ship with a --max-blobs flag that will limit the number of blobs that the client will propose blocks with. Theres no point in building a block with more blobs than you can upload, so this will be a good way to ensure you don't miss any proposals. This feature is still a WIP and may not be available in your client as soon as you update to a mainnet compatible release.
Devnet Data
Taking a step back from the theoretical requirements, we can look at the data collected from our devnets to get a better sense of the requirements for the network.
- Multiple devnets were run over the last few months, but we will focus on data from fusaka-devnet-5 due to its size.
- ~1700 node devnet (1/8th mainnet) that was deployed in collaboration with Sunnyside labs.
- 5 BPOs were configured that tested blob counts as high as 72 blobs. We will focus on the range below 21 blobs as those are the suggested max values for BPO1 and BPO2.
- We test against our existing node types (supernodes, validating nodes, full nodes) as each has differing requirements.
Nodes used for testing
Our infrastructure looked as follows:
- For Supernodes:
- 8 vCPU/32GB RAM/640GB SSD
- 1000 Mbps upload and download speeds
- For Validating nodes:
- 8 vCPUs / 16GB RAM
- 100/50 Mbps Download/Upload limited using traffic control
- Some ARM nodes were also run with varying number of validator counts
- For Full nodes:
- 4 vCPUs / 8GB RAM
- 50/15Mbps Download/Upload limited using traffic control
- Run by the Sunnyside Labs team
During the test phase, we always had 2 phases per BPO. Half the duration was spent using MEV and the other half utilizing local building alone. This allowed us to collect datapoints for both types of network setups.
Devnet observations for BPO1
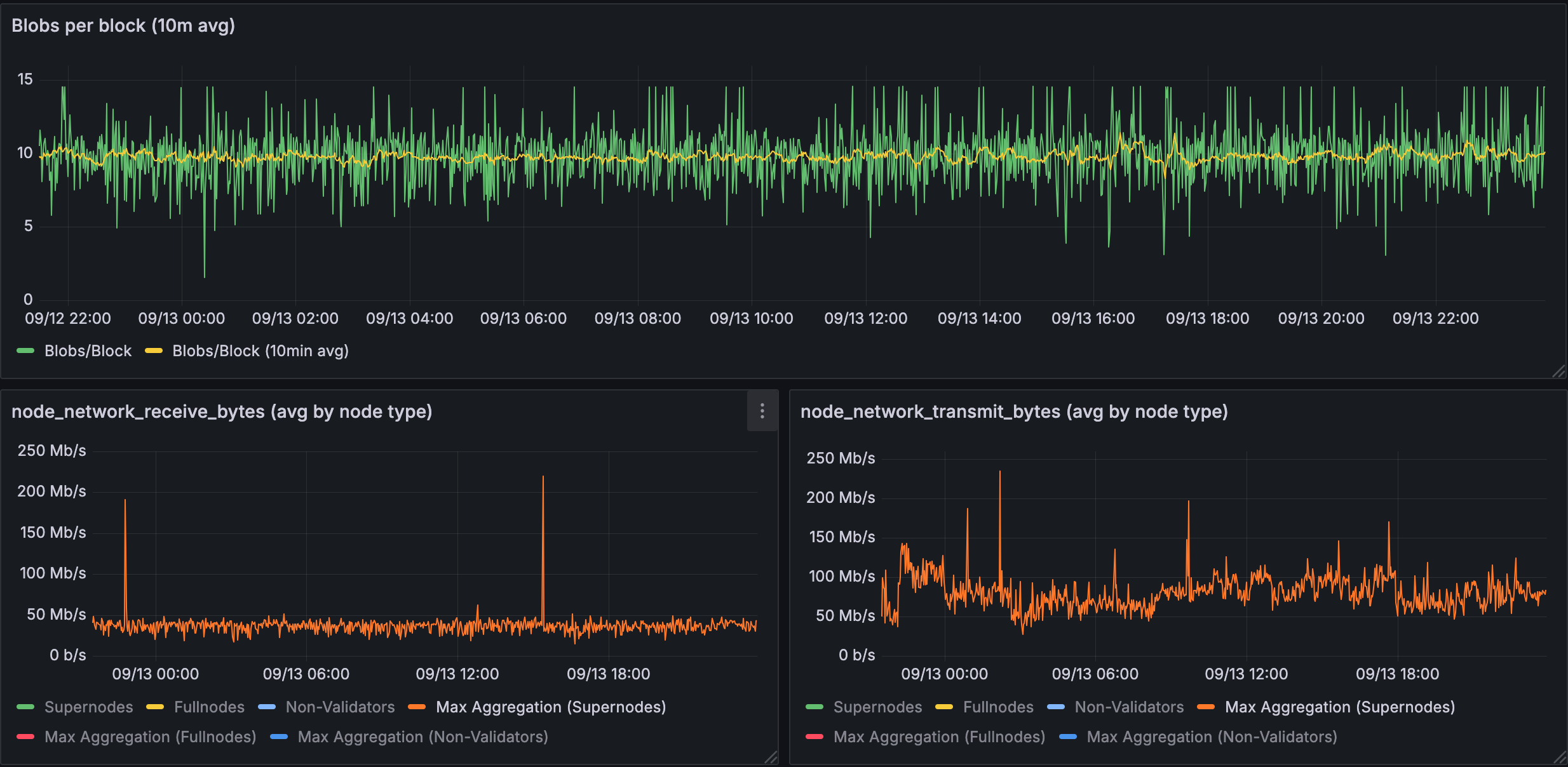
Figure 1.1: Bandwidth used for 10 blobs in a supernode
Supernodes show significant bandwidth spikes with 10 blobs: receive peaks at ~200 Mb/s, transmit peaks at ~250 Mb/s, with baselines around 50-100 Mb/s.
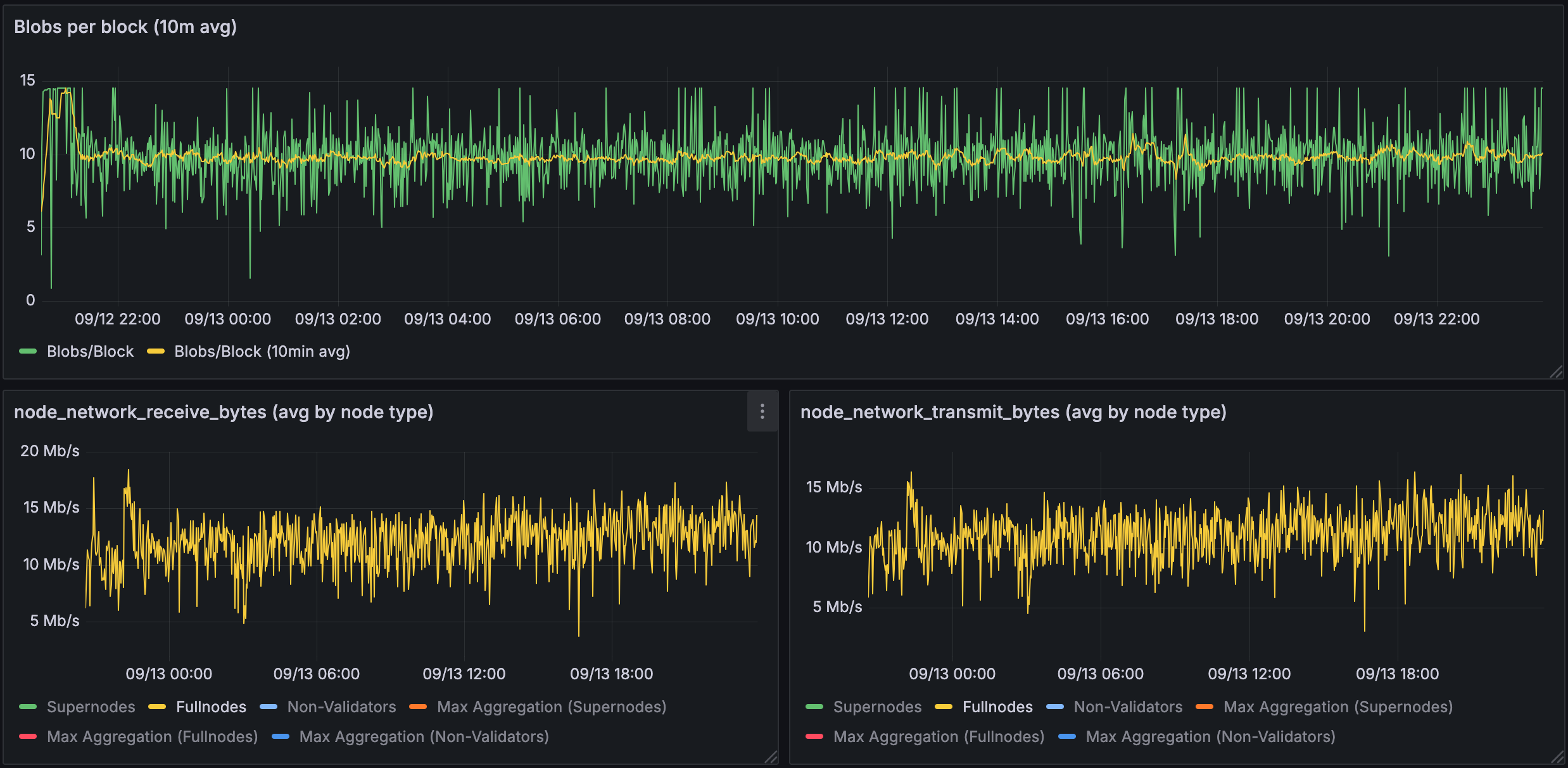
Figure 1.2: Bandwidth used for 10 blobs in a validating node
Validating nodes (home stakers) show dramatically reduced requirements: ~15-20 Mb/s receive, ~10-15 Mb/s transmit. This demonstrates PeerDAS's key benefit to home stakers.
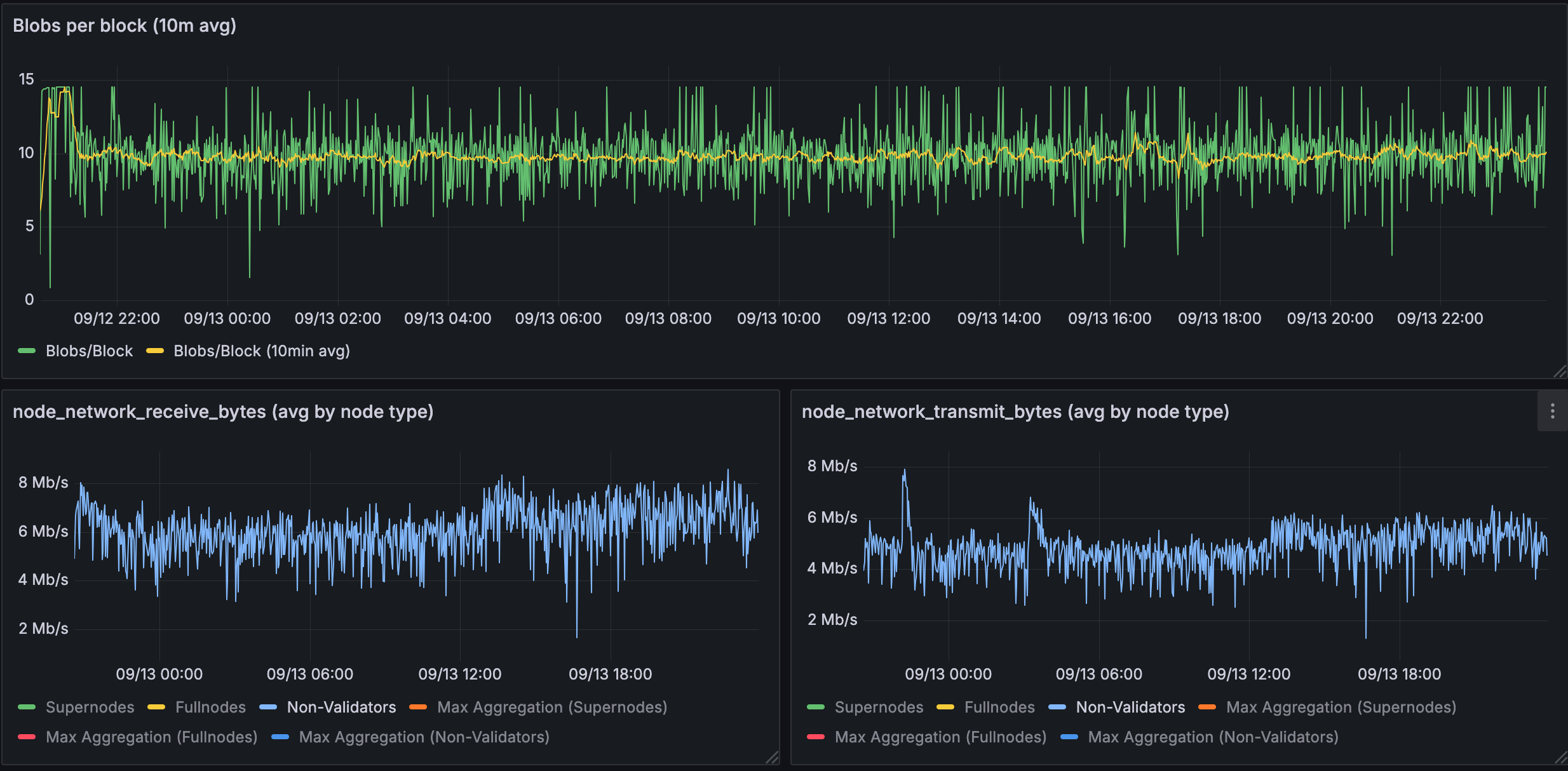
Figure 1.3: Bandwidth used for 10 blobs in a fullnodes
Full nodes have minimal bandwidth needs: ~4-8 Mb/s for both receive and transmit.
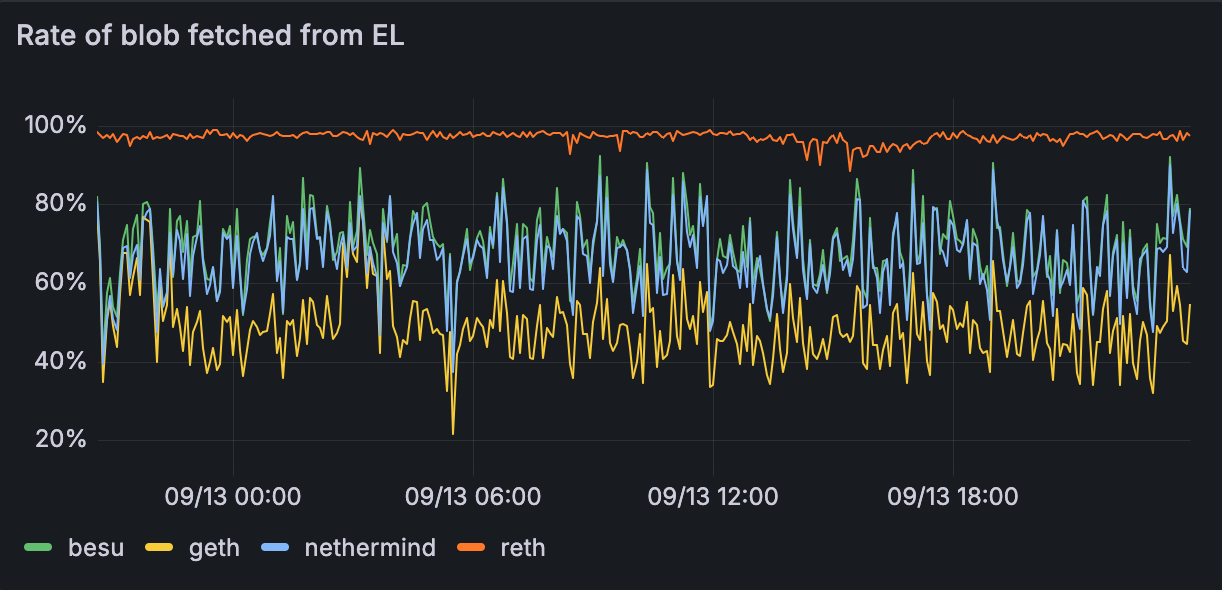
Figure 1.4: % of blobs fetched from EL instead of via gossip
The data shows significant variation in blob retrieval strategies across the network, with fetch rates from the Execution Layer ranging from 40-100%. This implies that a large section of blobs can be fetched before they are needed in the block validation pipeline, reducing the bandwidth needs at the critical portion of the slot. This data however is only from the devnet and is not proof that we'd see similar numbers on Mainnet.
Summary for BPO1: The observed bandwidth requirements for validating nodes (home stakers) at 10 blobs are well within EIP-7870 specifications, which require 50 Mbps download and 25 Mbps upload. Our devnet data shows peaks of ~15-20 Mb/s in both directions, leaving headroom for other operations.
Devnet observations for BPO2
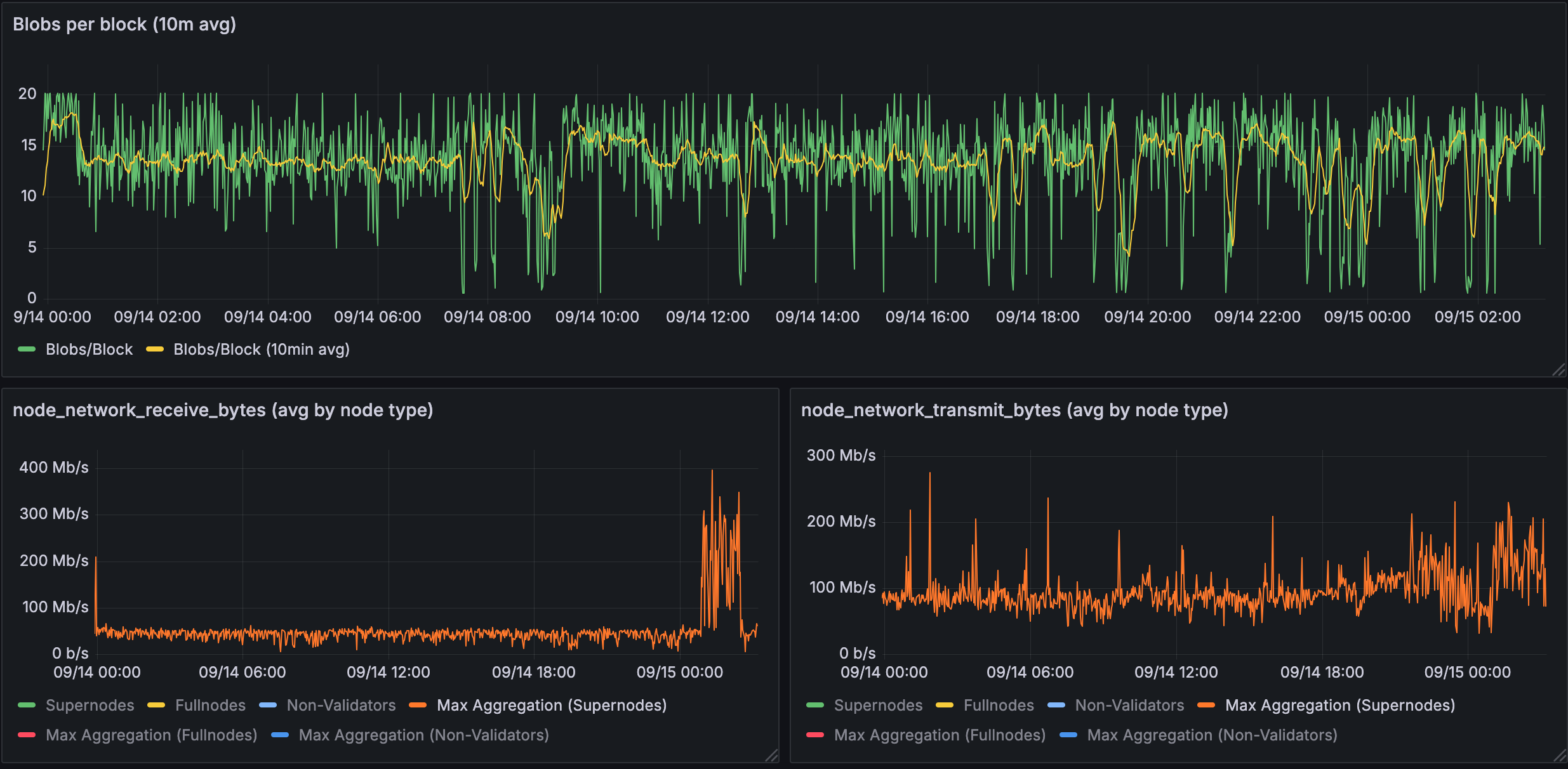
Figure 2.1: Bandwidth used for 14 blobs in a supernode
With 14 blobs, supernodes face increased demands: receive spikes to ~400 Mb/s, transmit to ~300 Mb/s. However, ignoring the spikes, the baselines data usage seems to be around 100 Mb/s. The higher blob count clearly amplifies bandwidth requirements for supernodes.
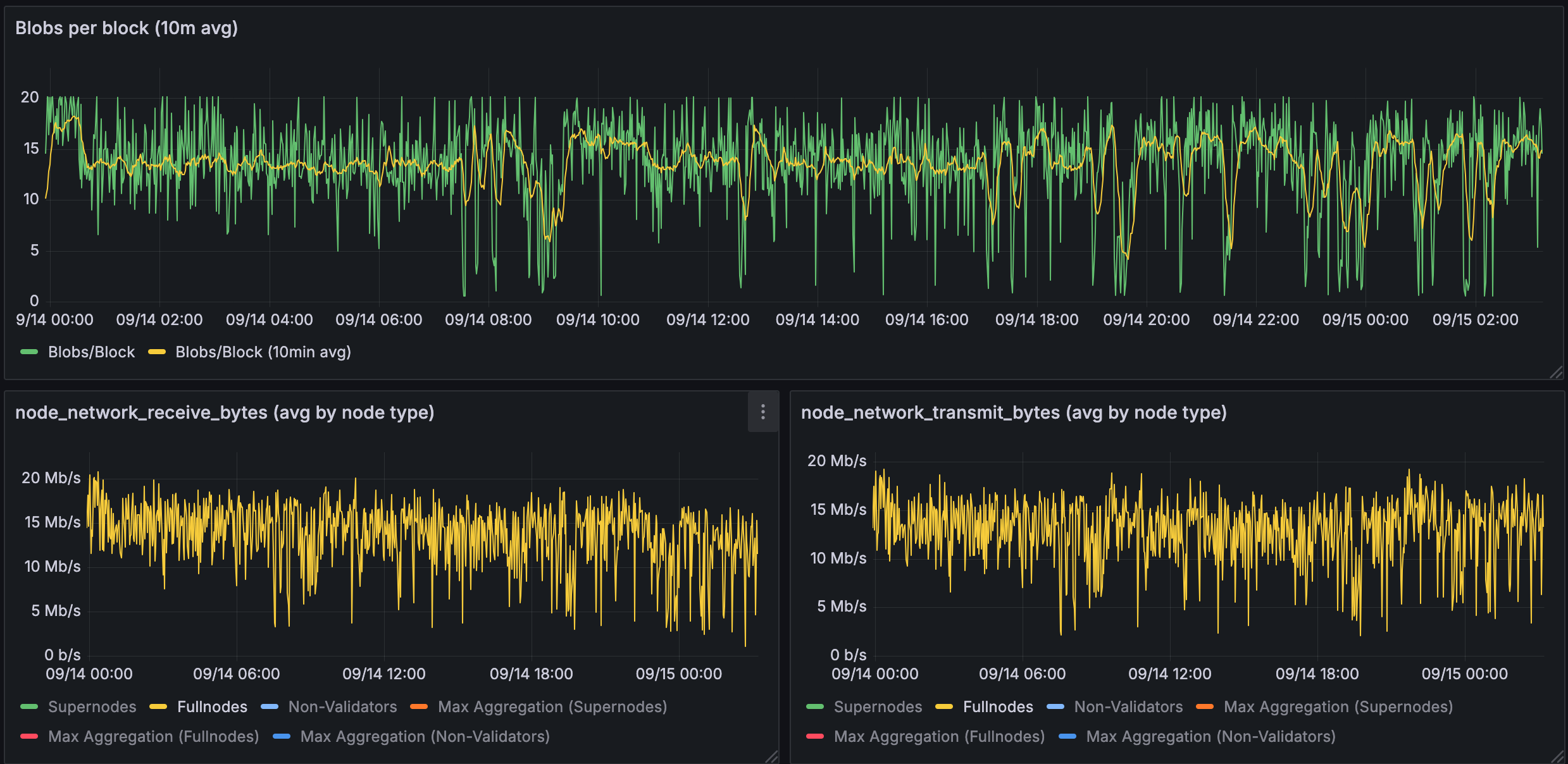
Figure 2.2: Bandwidth used for 14 blobs in a validating node
Validating nodes maintain reasonable requirements even at 14 blobs: ~17-25 Mb/s for both directions.
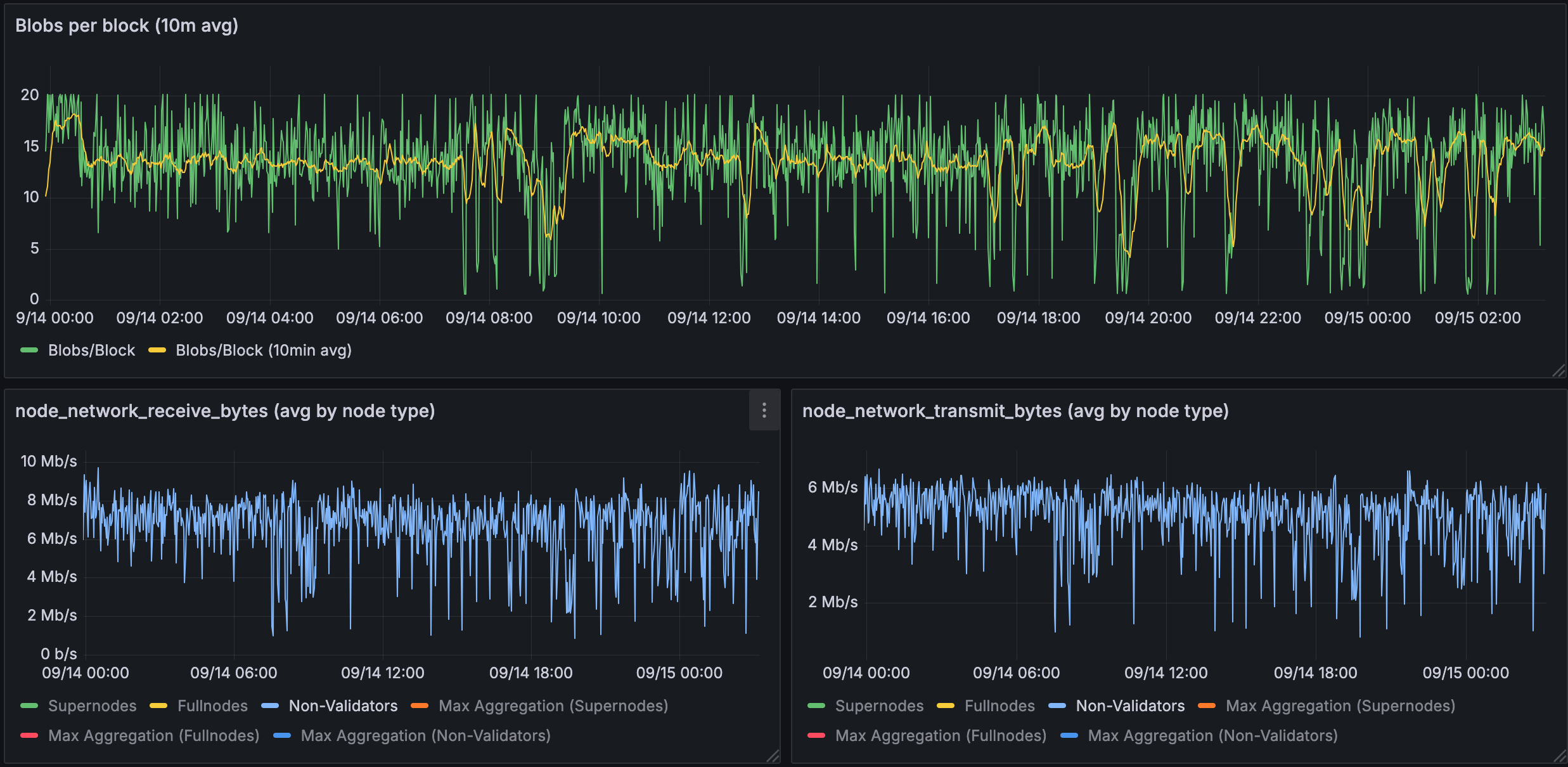
Figure 2.3: Bandwidth used for 14 blobs in a fullnodes
Full nodes continue to show minimal bandwidth requirements at 14 blobs: ~8 Mb/s for both receive and transmit.
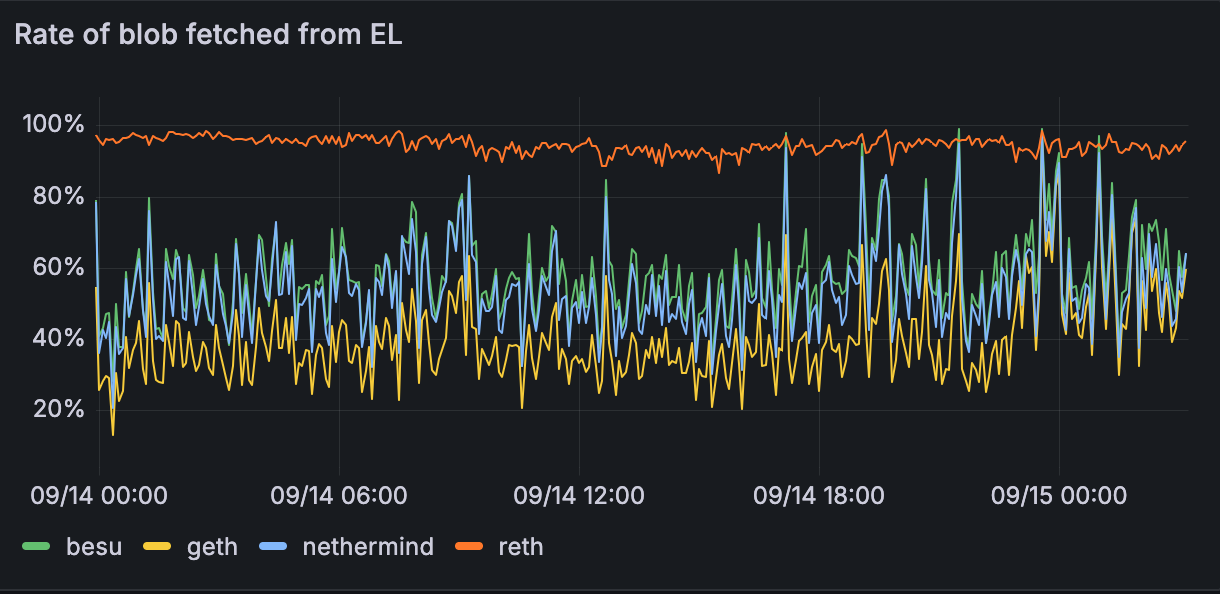
Figure 2.4: % of blobs fetched from EL instead of via gossip
At 14 blobs, the network continues to show varied blob retrieval patterns, with EL fetch rates ranging from 20-90%. We see that the hit rate reduces with an increasing number of blobs even for controlled networks. This data however is not representative of Mainnet behaviour and we'd need additional monitoring to understand the behaviour on Mainnet.
Summary for BPO2: Even at the higher blob count of 14, validating nodes remain within EIP-7870 bandwidth limits for home stakers (50 Mbps download, 25 Mbps upload). The observed ~17-25 Mb/s in both directions still is achievable for the average home staker with local proposals.
General Caveats
- The BPO traffic is hard to nail down because it is unclear how much the public mempool traffic will account for with increased blobs. Theoretically, the mempool should see more traffic as we increase the target blob count - but this is only an assumption due to the existence of private mempools.
- The values provided in the document can be used as high level guidelines, please ensure that you have additional bandwidth available to account for engineering margins. Once Fusaka is live on Mainnet, we would obtain live data and can update the analysis with more accurate information.
- Theoretical values proposed earlier in the document do not capture the nuances of running a node such as mempool traffic on the EL, providing sync state to peers and other background gossip.
Summary
- Home stakers: Validating nodes require ~25 Mb/s bandwidth (within margins of EIP-7870 limits), allowing Mainnet to scale to 14 blobs safely.
- Effective load distribution: Supernodes handle backbone requirements (200-400 Mb/s peaks) while full nodes operate minimally (4-8 Mb/s), demonstrating PeerDAS's scalability benefits.
- Distributed blob building helps: Local blob retrieval from execution layer mempools can help reduce gossip bandwidth during critical validation periods.
This data supports proceeding with Fusaka's rollout schedule while maintaining decentralization. We will continue to monitor the Fusaka rollout on Mainnet as conditions may differ from devnet testing.
Follow up reading:
Please also read the analysis provided by the Sunnyside labs team, found here. They go into significantly more detail about the breakdown of types of traffic as well as optimisations.