

Intro
Fusaka is quickly approaching, and it's time to start picking Blob Parameter Only fork values. These are mini hard forks where the only thing that changes is the blob count. They provide a mechanism for core devs to safely scale the chain without the coordination overhead of a fully-fledged hard fork. The current idea amongst devs is to ship Fusaka with safe initial blob count values, collect data, then more aggressively scale up with more confidence shortly after.
But what do we set those initial values to? We need to pick values that will be safe while also providing enough data to provide insight in to future BPO values. Enter fusaka-devnet-5.
Fusaka-Devnet-5
In collaboration with Sunnyside Labs ❤️
This network is more of a smoke test than anything. We’re checking things work on a fundamental level but not much beyond that.
The network has a high node count (1-2k) to help bridge this gap, but this is still ~1/8th of Mainnet. Unfortunately this brings a certain amount of chaos. Individually tending to nodes becomes unviable, and the holes in the ship quickly become insurmountable for humans to plug. As of time-of-writing there is between 50-100 nodes that are failing to attest correctly above a 50% rate.
Throughout the lifecycle of this network we've also stepped on a few rakes:
-
Node misconfigurations
Due to a misconfiguration in the Ansible on the ethPandaOps side, ~700 "full" nodes were custodying all columns while being bandwidth limited. This was fixed around 6PM UTC 17/09/25.
-
Multiple client bugs
This is a great outcome - it's always better to find these in the devnet cycle, but it provides another layer of noise to the data that is challenging to cut through.
Given the above there is only a relatively small window of usable data (~12hrs). This is additionally challenging as some of the testing scenarios are relatively low volume. Given this landscape, we have fairly low confidence in the data found here, but it should do the job for unblocking us on initial testnet BPO values. We will likely run a fusaka-devnet-6 in the coming weeks to improve confidence in the numbers found here.
Analysis
We'll focus on the viability of these Max Blob Count options:
We utilize a metric called Head attestation immediately correct %. We define this as an attestation that voted for the block in their duty slot (not a parent block). This means that the validator saw the block and the required columns before 4s. If an attester votes for a parent block it means they didn't see the block/columns in time. This bundles up a lot of the complexity within the network, like distributed blob building, propagation, block processing time, etc, into a nice single metric.
With Xatu we have the ability to filter and group this data on both the proposer side AND the attester side on multiple dimensions. E.g. "Show slots that were proposed by all supernodes and attested to by Lodestar regular nodes when proposed via mev-relay, grouped by proposer CL type"
Test 1: Can a full node propose a block without MEV-Boost?
As per EIP-7870, full nodes have 50mb of upload bandwidth to play with. They have to gossip all 128 columns to their peers, and 66% of the slots attesters have to see those columns before 4s. This is a tough ask for our most bandwidth sensitive network contributors as the blob count scales, and we'd expect to hit a tipping point somewhere here.
Data Filter
- 12 hours of data
- Only locally built blocks
- Proposed by full nodes
- Excluding Prysm as it had a block proposal bug throughout the time window
- Excluding Nimbus as it is a severe outlier and indicates client specific issues
- Attested to by all node types (full + super)
- Excluding Nimbus (same reason as above)
- Excluding Lodestar as it has a sizable amount of nodes with issues throughout the time window
This network only has 10% of the effective balance running on full nodes. Combined with needing to filter out Prysm & Nimbus proposals, which are 40% of our full node effective balance, we're really struggling for data. Nonetheless we can still dive in.
Results
Given the above, we only have 100 slots of data to work with. We're really only checking if these blob counts are fundamentally possible though, which helps.
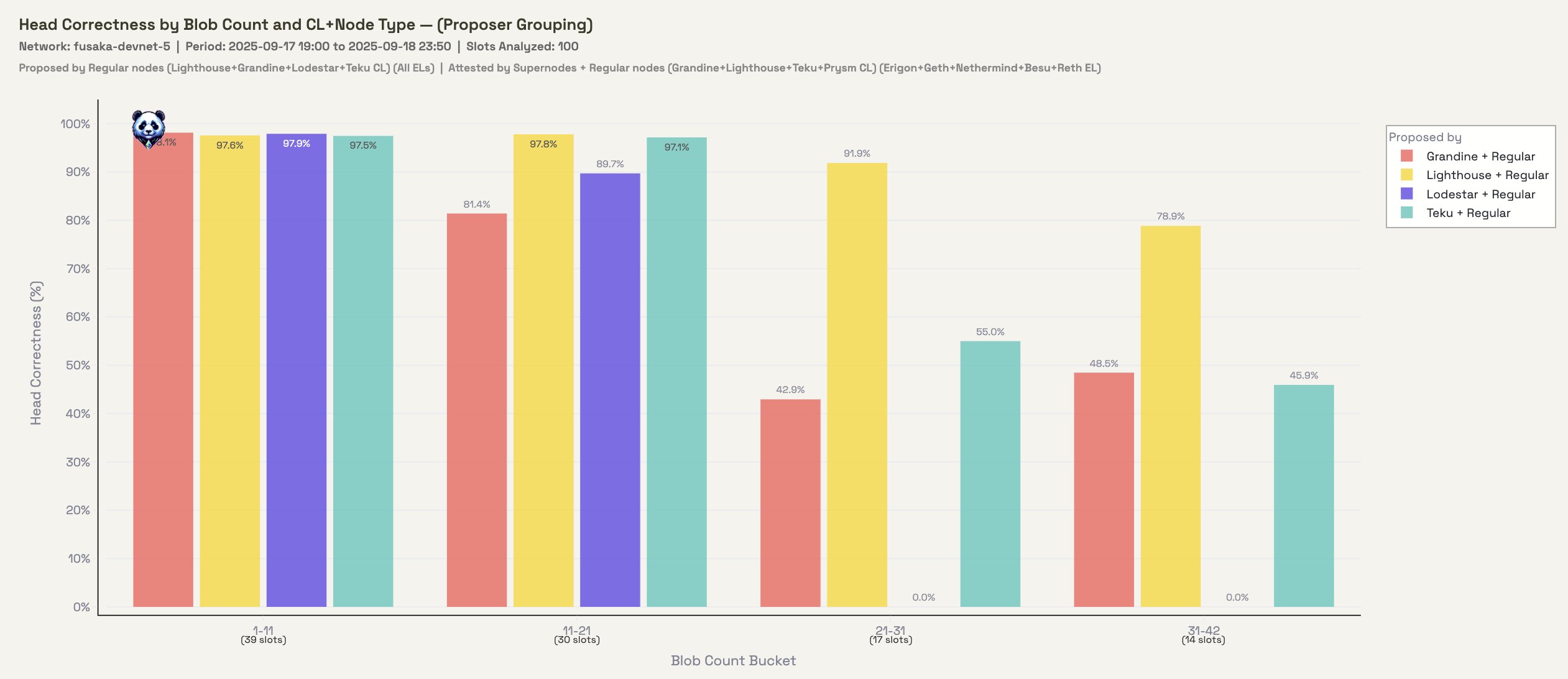
Figure 2.1: Head Correctness grouped by proposer CL
Focusing on the proposer side here, there appears to be a fall off past 21 blobs. Lighthouse is a strong performer.
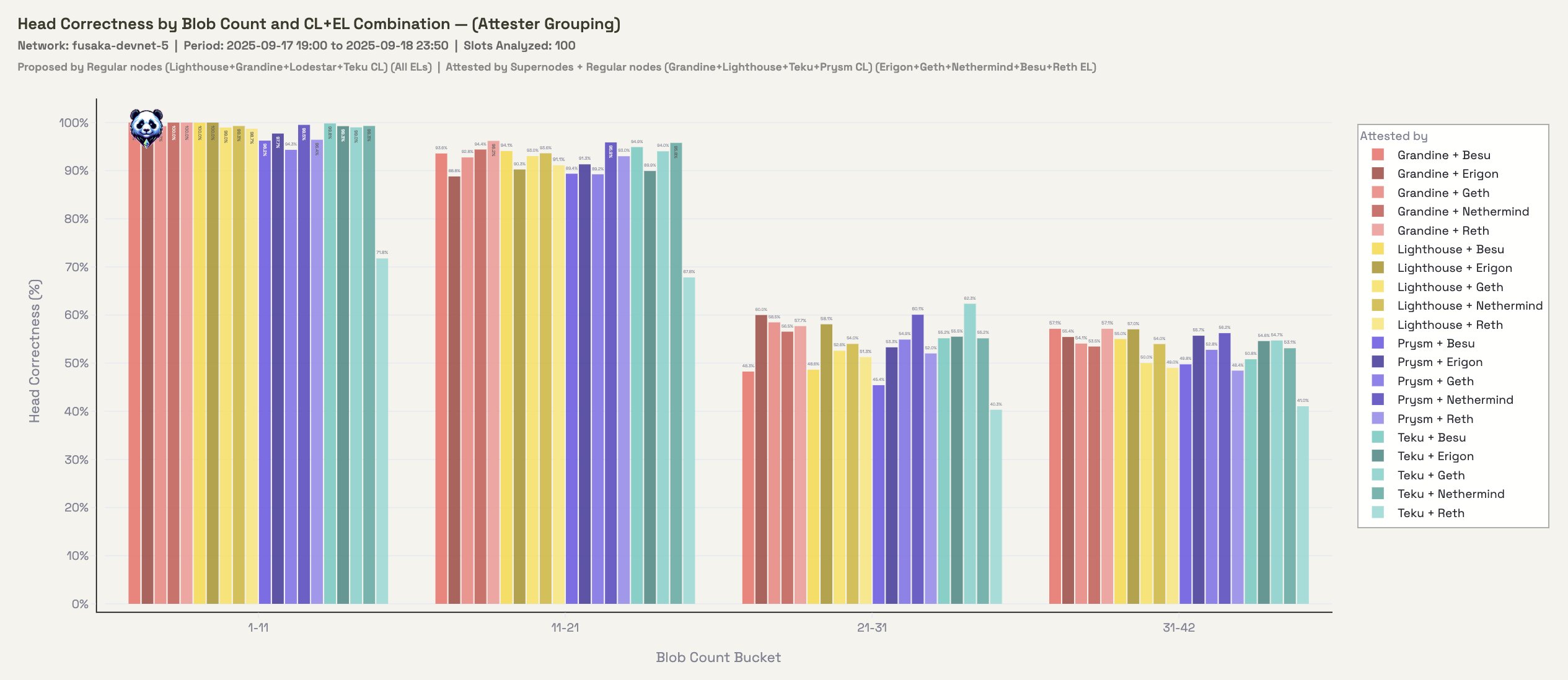
Figure 2.2: Head Correctness grouped by attester CL-EL
Looking at the attester side of the equation here. This is observed across all attester CL-EL combos which indicates that the proposers are under stress.
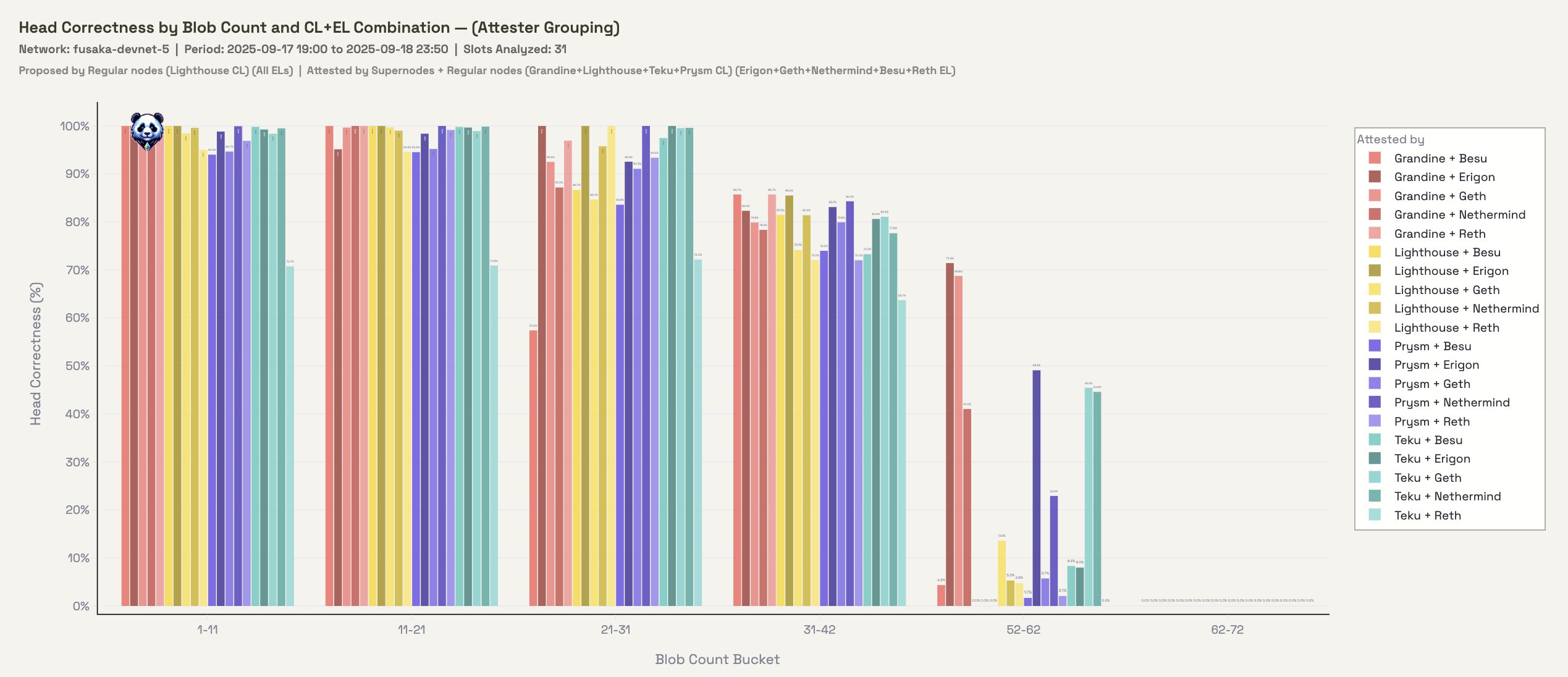
Figure 2.3: Head Correctness grouped by attester CL-EL for blocks proposed by only Lighthouse
We noticed strong proposed performance with Lighthouse earlier so we can zoom in on just their block proposals. Surprisingly, the 21-31 blob bucket is showing signs of life and is theoretically possible. This indicates that there may be more juice to squeeze out of clients when it comes to pushing the blob count for our bandwidth sensitive operators. Maybe theres something lurking in libp2p implementations? One for the philosophers.
Outcome
Test 2: Can supernodes see 128 columns at max blob count on time?
Nodes will only attest to a block once they see all the columns they're custodying. In the case of Supernodes, this is all 128 columns. We need to assert that these nodes can consistently see all columns well-before 4s. The worry is that it only takes 1 column to arrive late and a large % of validators won't attest to the block.
Data Filter:
- ~14 hours of data
- All block sources (local & mev relay)
- Proposed by supernodes
- Excluding Prysm as it had a block proposal bug throughout the time window
- Excluding Nimbus as it is a severe outlier and indicates client specific issues
- Attested to by supernodes
- Excluding Nimbus (same reason as above)
- Excluding Lodestar as it has a sizable amount of nodes with issues throughout the time window
Results
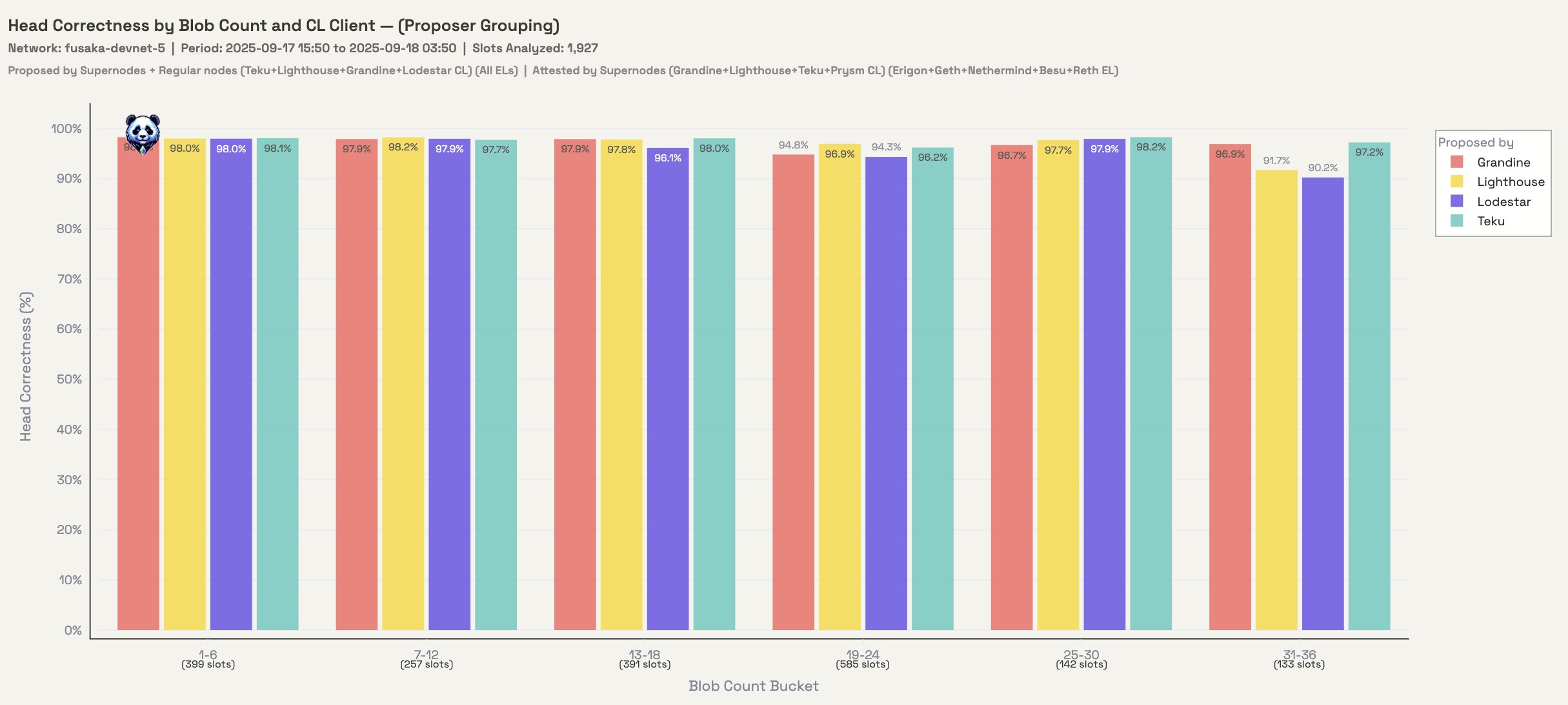
Figure 2.1: Head Correctness grouped by proposer CL
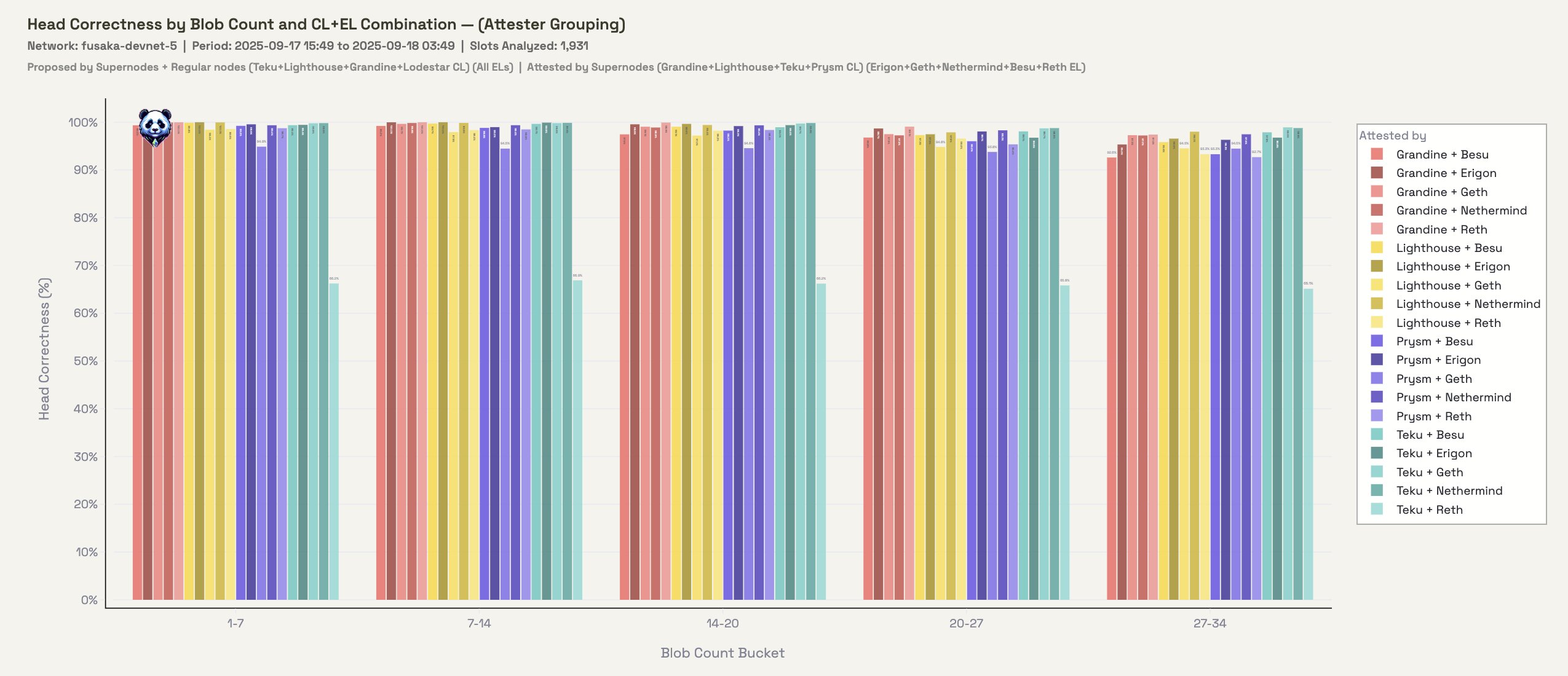
Figure 2.2: Head Correctness grouped by attester CL+EL
Both sides of the equation here show strong results. We don't appear to be hitting any bottlenecks in this configuration as blob count increases.
Test 3: Can the network recover columns in time?
If the proposer fails to publish a single column, can the network recover that column in time to save the slot? Some Lighthouse nodes have been configured to randomly withhold a column when they propose blocks.
Results
All tested slots successfully recovered the withheld columns and became canonical, achieving immediate attestation correctness that is around par for the network.
Test 4: Can new nodes join the network?
Syncoor has been deployed to fusaka-devnet-5, and has been doing frequent sync tests. Shoutout to Skylenet on our team for this shiny new tool! The Syncoor UI has in depth metrics around runtime and utilization.
Results
New nodes are able to join the network in a pretty linear time fashion across both full nodes and supernodes. Syncoor conducted ~3500 sync tests over the duration of the network 👑
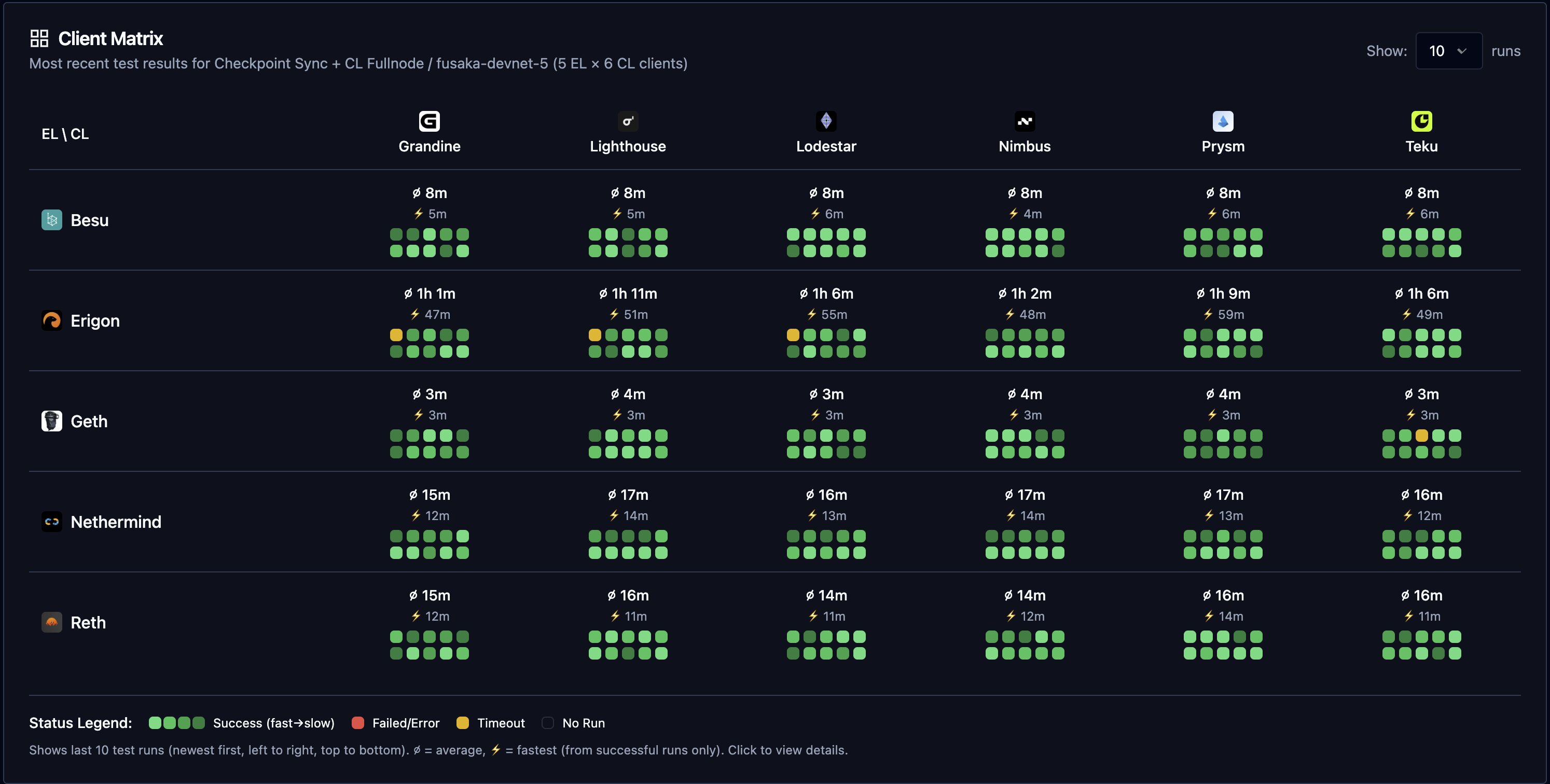
Figure 4.1: Full nodes are able to sync to the head of the network
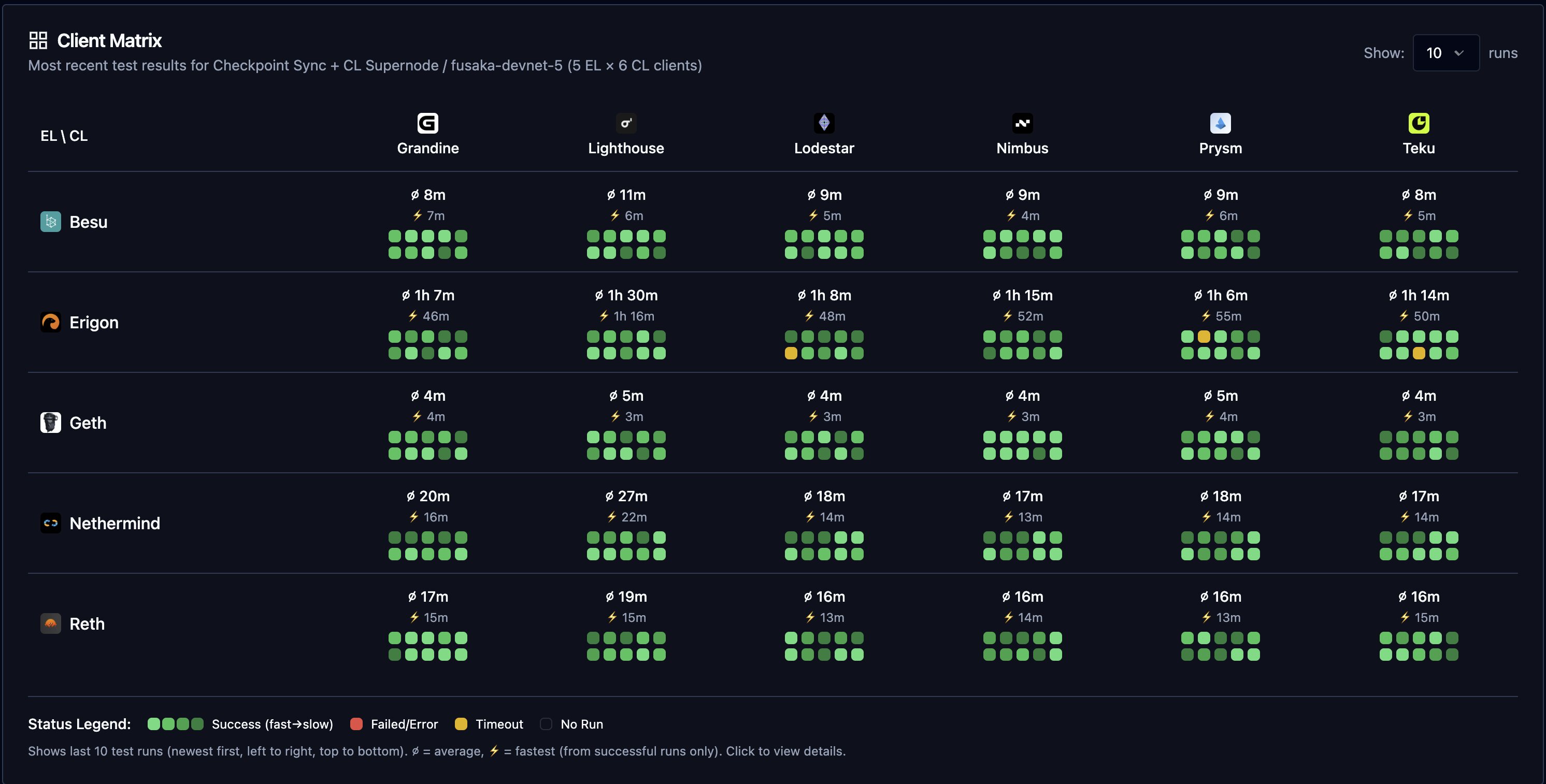
Figure 4.2: Super nodes are able to sync to the head of the network
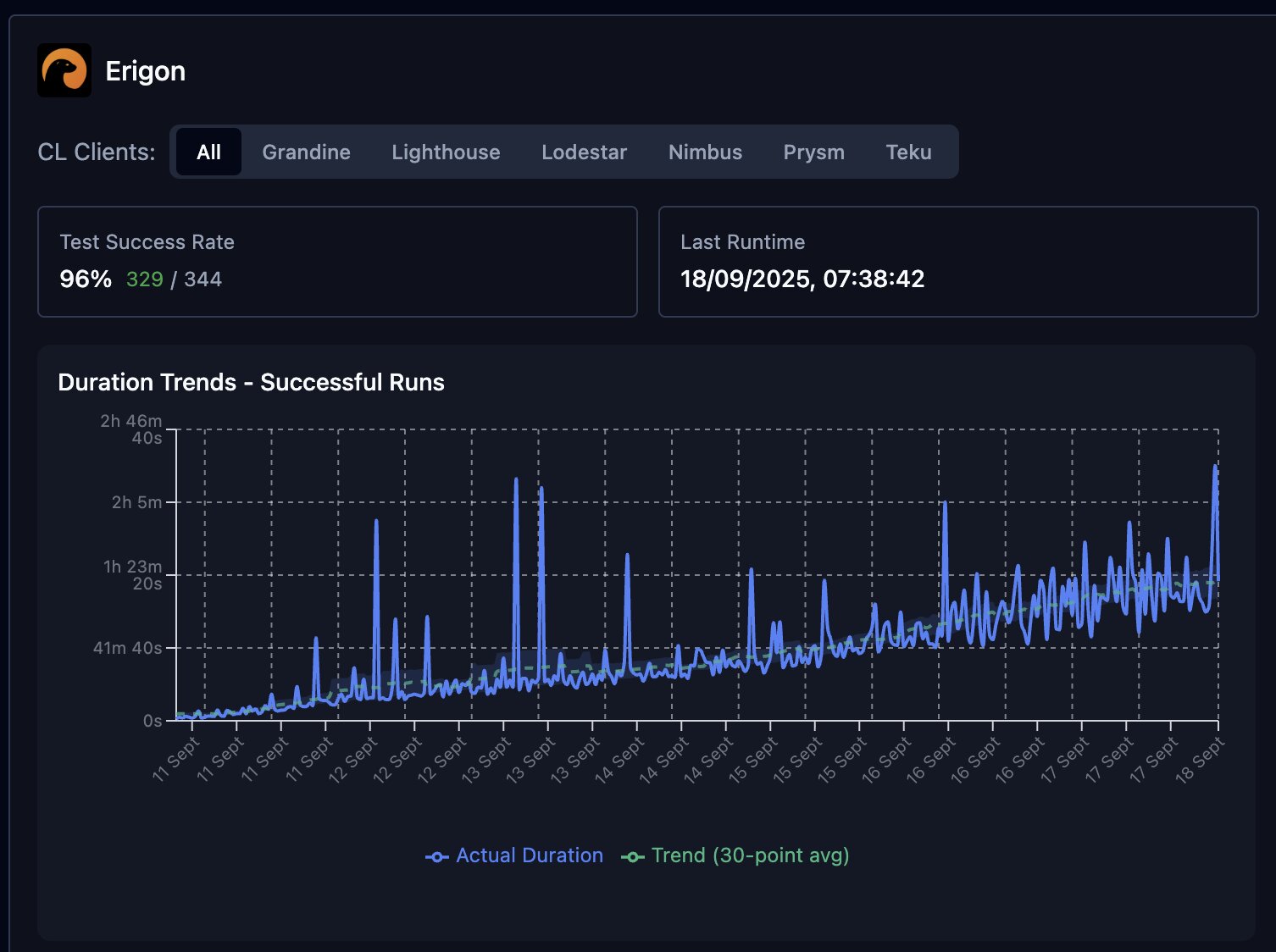
Figure 4.3: Erigon sync times on fusaka-devnet-5
Erigon is a bit of an outlier here. It's times are increasing at a substantial rate, and it is generally much slower than other ELs, but this is most likely related to the lack of torrent infrastructure on the network. This is something we're working on and will be available in the near future.
Conclusion
fusaka-devnet-5 provided more challenges than we were hoping but still provided valuable insight in to how the network performs as the blob count increases. It must be reiterated that the data collected here has a small sample size, and that fusaka-devnet-5 does not represent Mainnet.
A safe starting point
Test Results
Better data for future increases
Test Results
Notable challenges
Test Results
Potential Initial BPO Schedule
Given the viability of the above, we propose a schedule that combines safety, throughput increases, and enough data to inform future BPO decisions. As we go through the testnet stage for Fusaka this may need to be adjusted as new data comes to light.
| Phase | Target Blobs | Max Blobs | Change | Notes |
|---|---|---|---|---|
| Electra | 6 | 9 | Live now | |
| Fusaka | 6 | 9 | +0% | Initial PeerDAS activation |
| BPO 1 | 10 | 15 | +67% | Few weeks after Fusaka |
| BPO 2 | 14 | 21 | +40% | Few weeks after BPO 1 |
Thanks
Shoutout to the client teams who worked closely with us throughout this devnet, and to the Sunnyside Labs team who ran a large amount of nodes!
🚀🚀🚀