


If you ask an AI model about consensus constants, EVM execution, or state transitions, does it actually know what it's talking about? We built EthIQ, a benchmark that measures how well AI models understand Ethereum protocol internals.
Models are tested in two modes: API (direct API calls with a system prompt, no tools) and Agentic (CLI tools like Claude Code and Codex running in sandboxed Docker containers with bash, file I/O, and Node.js).
Motivation
LLMs are now a daily tool at ethPandaOps, and we needed a way to evaluate them in our specific context. EthIQ gives us a quick signal when a new model releases, and a meaningful eval suite to drive improvements as we invest more in agentic tooling (prompt optimization, fine-tuning, workflows, etc.)
Questions
The question set is designed to stress two distinct model capabilities: world knowledge (tested by categories like Constants) and raw reasoning (tested by auto-generated categories like EVM Execution). World knowledge questions are intentional. We want to explicitly probe what Ethereum protocol knowledge made it into a model's training data, since recall of these values is genuinely useful.
To prevent memorization in the raw reasoning tasks, auto-generated questions start from official Ethereum spec test fixtures but mutate the inputs with a randomized seed (balances, storage values, calldata, deposit amounts, etc.) Ground-truth answers are then re-derived from the mutated inputs using the Python reference implementations. If a model saw the original fixtures during training, its answers won't match. New forks get a fresh seed, keeping the benchmark honest over time.
Questions are organized into datasets tied to Ethereum forks. The first dataset is fusaka, with 325 questions across these categories:
| Category | What it asks | Example |
|---|---|---|
| Constants | Exact protocol constant values | What is the value of SLOTS_PER_EPOCH on Mainnet? |
| EVM execution | Trace through bytecode, report the outcome | Given 0x..., what's in storage slot 0x1? |
| Consensus state transitions | Apply slashings, deposits, etc. and compute resulting state | After this attester slashing, what is validator 6's balance? |
| Consensus epoch processing | Calculate rewards, penalties, and balance deltas | What are the reward/penalty deltas after processing this epoch? |
| Consensus fork choice | Replay block trees and determine the canonical head | After these attestations, which block is the head? |
| Consensus shuffling | Compute validator committee assignments | Which validators are in committee index 2 at slot 4? |
| Calculations | Multi-step arithmetic using protocol constants | How many seconds are in one Ethereum epoch? |
| Conceptual | Open-ended explanations graded by LLM rubric | Explain how RANDAO bias works in validator shuffling |
| Cross-fork | What changed between forks | What changed about max effective balance in Electra? |
| EIP interactions | How specific EIPs interact with each other | How do EIP-4844 blob commitments appear in beacon blocks? |
| Trick | Questions with wrong premises | "When did Verkle Trees ship on mainnet?" (They didn't.) |
The Results
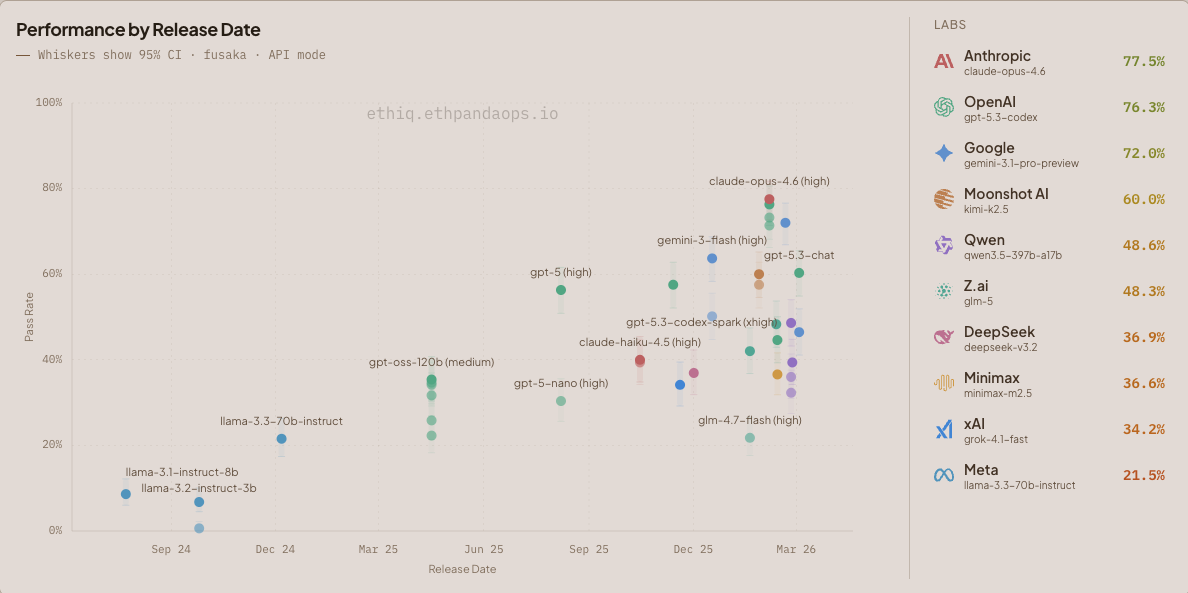
Figure 1: Model performance by release date on the fusaka dataset (325 questions). Whiskers show 95% confidence intervals.
Frontier
In API mode, Anthropic's claude-opus-4.6-high leads at 77.5%, followed by OpenAI's gpt-5.3-codex-xhigh at 76.3% and Google's gemini-3.1-pro-preview-high at 72.3%. claude-sonnet-4.6-high is still in progress.
When Agentic runs are included, gpt-5.3-codex-xhigh takes the lead at 83.7% via the Codex CLI.
We observed some models (minimax-m2.5-high) suffering degraded performance as their reasoning_effort increased. After investigation, we found that these models were exhausting their maximum token output allocation, effectively thinking themselves to death.
EVM execution questions in API mode are a particularly good vibe check for model capability. Watching Kimi K2.5 step through executing the EVM in it's thinking traces is quite an experience (read: concerning!) We felt bad asking llama-3.2-1b to do the same. In general, we weren't expecting models to be so capable at executing the EVM in-context. Fortunately we capped the difficulty of the EVM questions at generation time (based on a few heuristics), so once this dataset set begins to saturate we can raise these limits and unleash a new very hard class of questions.
Open Weights
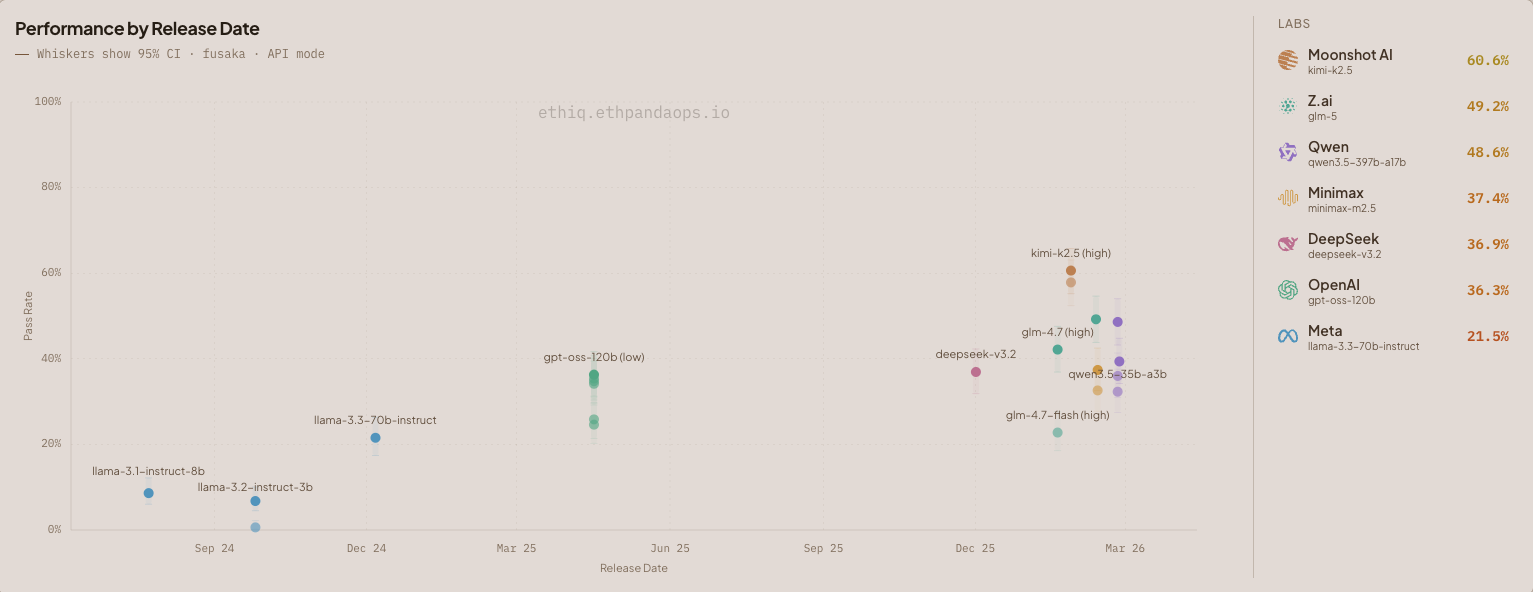
Figure 2: Open Weights model performance by release date on the fusaka dataset (325 questions). Whiskers show 95% confidence intervals.
Ethereum and open weights models go hand-in-hand, so we added the ability to show just open weight models. Kimi's k2.5-high is the stand out amongst the open weight models, scoring 60.6%.
minimax-m2.5-high was disappointing, landing at 37.4%. This bulk of this disparity is in Consensus Constants, with k2.5-high at 94.7% compared to minimax-m2.5-high at 58.9%. k2.5 is a much larger model at 1 trillion parameters versus minimax-m2.5 at 230 billion. World knowledge is an important factor when using an LLM for Ethereum!
The Canary 🐦
Thankfully all API evaluations returned failures for Consensus shuffling. This would require the models to compute SHA256 in-context. If this canary dies you'll find the ethPandaOps team in a remote location far away from any electricity.
Try it
Browse the full results at ethiq.ethpandaops.io. You can filter by question category, difficulty, and evaluation mode.
Keep an eye out as we'll be updating this as new forks ship and models are released!